k-nearest neighbors is a very simple algorithm used to solve classification problems.
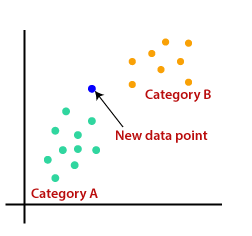
To Understand and Implement the algorithm Visit – k-nearest neighbors in Machine Learning (k-NN)
Advantages
1. k-NN is called Lazy Learner (Instance based learning). It does not learn anything in the training period. There is no training period. It stores the training dataset and learns from it only at the time of making real time predictions.
2. New data can be added without effecting the algorithm performance or accuracy
3. k-nearest neighbors Algorithm is very easy to implement. You need only two input
- Distance (e.g. Euclidean or Manhattan etc.) . Check of type of distance
- The value of K
Disadvantages
1. Performance Issue with large data-set: The time required to calculate the distance between the new point and each existing points is huge. Which then degrades the performance of the algorithm.
2. Does not work well with high dimensions / Features: The k-NN algorithm doesn’t work well with large no of Features dimensional data because with large number of Features , it becomes difficult for the algorithm to calculate the distance in each Features .
3. Value of K: It is really crucial to determine what value to assign to k. with different value of K you get different results
