K-Nearest Neighbors is one of the most basic classification algorithms in Machine Learning.
Code and Data-set Link : Github – StuffByYC | Kaggle – StuffByYC
Code and Data-set also available in Downloads section of this website
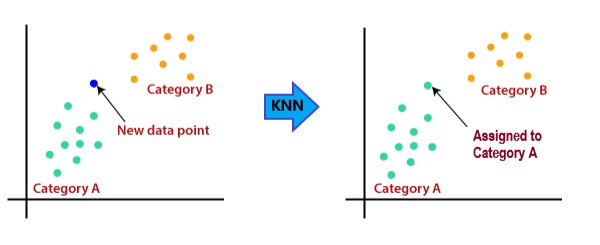
In this blog we will understand how K-Nearest Neighbors algorithm works. How to Implement it with Python.
KNN algorithm uses “feature similarity” to predict the values of new data-points based on distance.
To see type of distance used in distance based model go to: Type of Distances used in Machine Learning algorithm
Understanding K-Nearest Neighbor
What is K ?
k is the number of neighbors which will help us to decide the class of the new data-point.
Algorithm Steps:
Step 1: Choose the values of “K” that is. the number of neighbor which will be used to predict the resulting class.
Ex. Lets suppose we choose value of k as 5.
There are 2 classes [“Cat” , “Dog” ]. We have to predict if the new data point belongs to class “Cat” or “Dog”.
Step 2: Calculate the distance from the new data point to remaining data points and take k number of the shortest distant neighboring data point. you can choose which distance formula to use. Type of Distances used in Machine Learning algorithm
Ex. Lets suppose the 5 nearest data-point to the New data point “N( x,y ) “ are “A“, “B“, “C“, “D“, “E” that we calculated using euclidean distance method.
Step 3: After getting the “K” nearest data-points, count the categories of the data point ( That is count how many of those k neighbors belong to which categories).
Ex. The class of data points are
A – “Cat”
B – “Dog”
C – “Cat”
D – “Dog”
E – “Dog”
Now count the categories.
“Cats” – 2 and “Dog” – 3
Step 4: Assign the new data point “N” with the class having maximum categories count
Ex. Here category or class “Dog” has the maximum number of category count.
“3” out of “5” of the nearest data-point belong to category “dog”
So the new data point “N” will be assigned to class “Dog”
Let me know in comments if you have any difficulty understanding this.
Implementing K-Nearest Neighbor
Below we will Implement KNN Algorithm using Sklearn Library.
The task is to Predict if the Customer will purchase the product or not
Code and Data-set Link : Github – StuffByYC | Kaggle StuffByYC
Code and Data-set also available in Downloads section of this website
You need to install the Sklearn library
Open command prompt
pip install scikit-learn
Step 1: We will Import the Libraries

Step 2: Importing the data ( You can find the Sales.csv file in the Github Link above )

Step 3: Splitting Data into training and testing data
Here Test_size = 0.25. It means the out of the dataset that data Allocated for testing is 25%

Step 4: Feature Scaling
What is Feature Scaling ?
As we have learned above we are using distance to predict a particular class. Now in this particular data-set we have salary with value ranging from thousand to 100 thousand and the value of age is within 100.
As salary has a wide range from 0 to 150,000+. Where as, Age has a range from 0 – 60 the distance calculated will be dominated by salary column which will result in erroneous model so we need feature scaling
Feature Scaling is a technique to standardize/normalize the independent features (data columns) present in the data in a fixed range.

Below is the sample transition of data from
X(data) -> X (After train_test_split) -> X (After feature scaling)

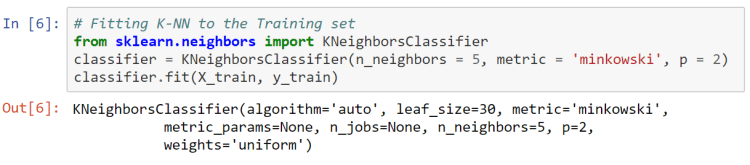
Step 5: Fitting the model
Here we will be using euclidean distance so we have set p = 2
Click on : Type of Distance to know more.
K value is set to 5
Step 6: Predicting the test result using the Classifier / Model

Step 7: Calculating Performance Metrics to Evaluate model
Click on Performance metrics to know more

True Positive (TP): Result data is positive, and is predicted to be positive.
False Negative (FN): Result data is positive, but is predicted negative.
False Positive (FP): Result data is negative, but is predicted positive.
True Negative (TN): Result data is negative, and is predicted to be negative.
Click on confusion matrix to know more



Click on accuracy to know more

Click on Precision to know more

Click on F1 Score to know more

Have successfully implemented K-Nearest Neighbors in python with the help of scikit-learn Library. check out Advantages and Disadvantages of K-Nearest Neighbors
